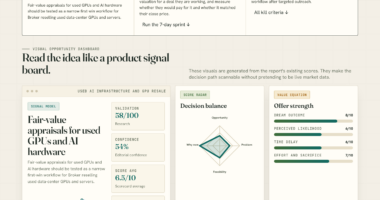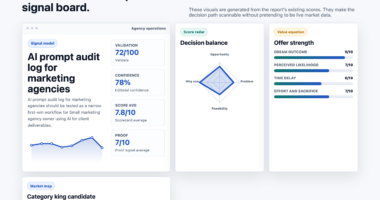

📊 Full opportunity report: Agentic Loop Failure Modes: A Production Taxonomy at the End of Year One on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
After a year of deploying agentic AI systems, researchers have established a detailed failure taxonomy covering 15 modes across six categories. This framework aims to improve debugging, evaluation, and architectural decisions in operational settings.
Researchers have finalized a production-oriented taxonomy of failure modes in agentic AI systems, based on data from the first year of deployment. This structured framework categorizes 15 specific failure modes across six categories, providing a vocabulary for debugging and guiding architectural decisions.
The taxonomy was developed through analysis of production reports, academic workshops at ICML 2026, and operational data from various deployments. It identifies failure modes such as drift, coordination failures, termination issues, and adversarial attacks, each with varying detection difficulty, recovery cost, and mitigation maturity.
For example, drift failures—like semantic drift—are common but hard to detect early, while tool interface failures are easier to mitigate but frequently occur. The taxonomy aims to help engineering teams prioritize investments in detection and mitigation strategies based on these categories.
Fifteen named failure modes.
First year of production agentic deployment is over. Year two is the structured-mitigation phase.
ICML 2026 has two dedicated workshops on the topic. Academic frameworks have arrived (Shahnovsky-Dror POMDP drift, Agent Drift study, AgentRx). Production reports have arrived (Agents of Chaos at OpenClaw, METR Task Complexity). The data is enough. The taxonomy is overdue. Six categories. Fifteen modes. Mapped to detection difficulty, production cost, mitigation maturity.
Six categories. Fifteen modes. Year one’s debugging vocabulary.
More granular taxonomies exist in the academic literature; they are useful for specific subdomains. For production engineering, the right granularity is the one a team can hold in working memory while debugging. Six categories is approximately that.

UJS Rocco OBD2 Scanner Bluetooth for iOS Android, AI Diagnostic Tool for Car Buying Repair, No Subscription Fee, AutoVIN, 45000+ Fault Codes, Check & Clear Engine Codes, Real-Time Data, Vehicles 1996+
AI-Powered Car Health Reports in Minutes: Get beyond confusing codes. Our Rocco OBD2 scanner connects to your phone…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
A bad assumption at step 3 contaminates step 50. Surfaces at step 200.
Failures rarely break at the obvious moment. The agent demonstrates plausible behavior at every individual step — but the trajectory has drifted. By the time anyone notices, the originating cause is hundreds of steps in the past.

Agentic AI Systems for Developers: A Developer’s Guide for Designing, Debugging, and Scaling Production-Ready Multi-Agent Systems
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Six categories. Six different priorities.
Production agentic systems should optimize their engineering investment in order of return-on-engineering, not moral hierarchy. Tool interface first (high frequency, easy fix). Adversarial last (catastrophic but rare).
The teams that adopt the taxonomy, invest in the eval harness, and implement the architectural patterns will capture the reliability gap and the customer trust that comes with it. Year two is the structured-mitigation phase.

HUPEJOS AI Dash Cam Front Rear Inside with Driver Monitor System, 360° Car Camera 4K, 4 Channel Camera for Cars, WiFi GPS, Dashcam 64GB SD Card, Night Vision, 24H Parking Mode, Upgrade DMS V8Plus
【4 Channel 360° All Sides Dash Cam】Drive with 360° camera for car using the dash cam. Four adjustable…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Four assignments. By role.
Build targeted probes for each named mode.
The eval-harness gap is the single largest unsolved problem for production agentic deployments. Build the targeting probes. Publish evaluation methodologies. The lab that produces a credible end-to-end agentic eval harness for the failure modes in this taxonomy captures durable strategic position. Current state of the art is fragmented; consolidation overdue.
Audit production systems against six categories.
For each: confirm whether targeted detection exists, whether the team can identify the originating step of a failure, whether mitigation patterns are in place. Most production systems have substantial gaps in state management, coordination, adversarial modes. Cost of remediation is high but lower than catastrophic incident cost.
Adopt the taxonomy as debugging vocabulary.
Library the failure-mode patterns. Implement at least the easy mitigations (tool interface, termination) before deploying. Invest in trajectory replay tooling early — debugging time savings alone justify engineering cost. Teams that systematically debug against the taxonomy ship more reliable agents than teams that don’t.
Submit to FMAI and FAGEN.
The field needs negative results, minimal reproductions, falsifiable mechanistic hypotheses. Current academic literature is heavy on framework proposals and light on operational definitions and minimal reproductions. The ICML 2026 workshops are explicitly soliciting both. Best Paper Awards available; non-archival venue allows dual submission.

Adversarial AI Threat Response and Secure Model Design: Practical Techniques for Detecting, Preventing, and Managing AI Vulnerabilities
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Operational Impact of the Failure Taxonomy
This taxonomy provides a crucial operational tool for engineering teams managing production agentic systems. It standardizes failure language, improves targeted evaluation, and informs architectural choices, ultimately reducing downtime and improving system reliability in real-world deployments. As agentic AI becomes more widespread, structured failure understanding is essential for safe and effective use.
First Year of Deployment and Emerging Data
Over the past year, multiple reports and academic workshops have collected failure data from production agentic AI systems. These deployments, ranging from email automation to complex task workflows, revealed recurring failure patterns. Prior to this, academic frameworks existed but lacked practical operational categorization. The recent data collection and analysis have now culminated in a formal taxonomy tailored to engineering needs, marking a significant step in operational AI safety and reliability.
“The data from the first year of agentic deployment has been sufficient to formalize a failure taxonomy that directly informs engineering practice.”
— Thorsten Meyer, May 2026
Remaining Unknowns in Failure Detection and Response
While the taxonomy categorizes failure modes and assesses detection difficulty, it remains unclear how universally applicable the categories are across different deployment contexts. The effectiveness of mitigation strategies for some modes, particularly drift and coordination failures, is still under evaluation. Additionally, the long-term evolution of failure patterns as systems and architectures mature is not yet fully understood.
Next Steps for Operational AI Reliability
Going forward, engineering teams will focus on developing targeted detection tools for each failure category, refining architectural patterns to mitigate high-risk modes, and conducting systematic evaluations based on the taxonomy. Further research will also explore the evolution of failure modes over extended deployment periods and across diverse use cases. Industry-wide adoption of this framework is expected to accelerate, leading to more reliable agentic systems.
Key Questions
What are the most common failure modes in production agentic AI systems?
Drift failures, particularly semantic drift, and coordination failures are among the most common and challenging to detect. Tool interface failures are frequent but easier to mitigate.
How does this taxonomy improve debugging in real-world deployments?
It provides a shared vocabulary to identify failure modes precisely, enabling targeted troubleshooting, reuse of mitigation strategies, and faster resolution of issues.
Are all failure modes equally likely or dangerous?
No, some modes like adversarial failures are rare but catastrophic, while others like tool interface failures are common and easier to handle. The taxonomy helps prioritize mitigation efforts accordingly.
Will this taxonomy evolve over time?
Yes, as systems mature and new deployment scenarios emerge, failure patterns may change. Ongoing data collection and analysis will refine and expand the taxonomy.
What role does this taxonomy play in architectural design?
It guides architects to select and implement patterns that target specific failure modes, balancing trade-offs between detection difficulty, mitigation maturity, and system complexity.
Source: ThorstenMeyerAI.com